Framework Architecture
The tool is presented as a framework and not as a simple application. SemTUI is developed as a prototype and it is intended to provide extendable components that can be selectively interchanged, added or modified by a developer. It should provide standard ways, mechanisms and solid structures to build additional functionalities or integrate new services.
Indeed, one of the non-functional requirements is to design components such that modularity is a top priority, so that future changes can be easily made without redesigning part of the existing application.
The framework combines both the powers of a web server and a client side application available as a web application. This structure enables a separation of concerns by separating the application into units, with minimal overlapping between the functions of the individual units. The separation is achieved using modularization and arrangement in the distinct software layers of the application.
In the figure below is shown the general architecture of the whole system. It is divided into two main parts and each of them is then layered with multiple software abstractions to handle different kinds of tasks.
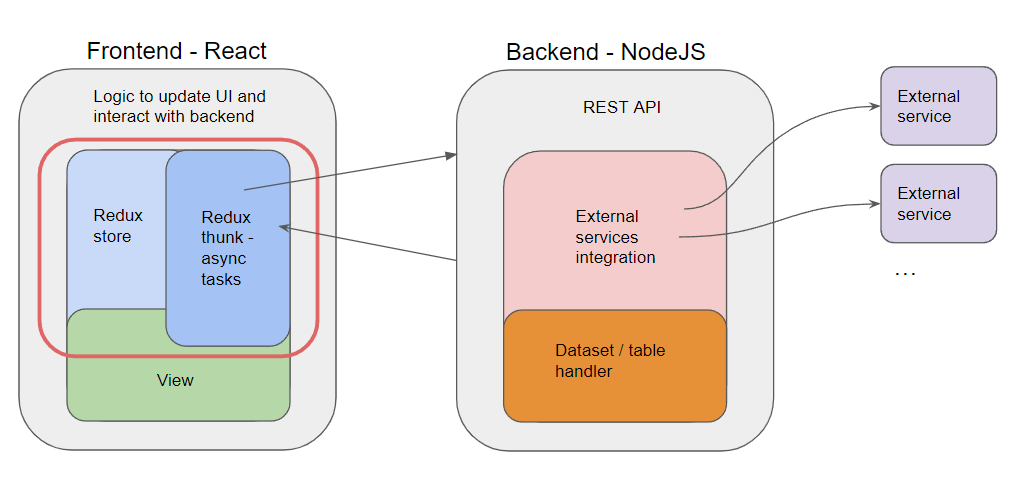
Frontend
It handles the interaction with the end user and provides all the functionalities necessary to the Semantic Enrichment of a table. It is a web application written using React and its sublayers enable to handle the application logic, communicate with the REST API, exposed by the backend web server, and rendering changes to UI components so that the logic is reflected.
Backend
It is mainly responsible of three tasks: it handles the integration and communication with any of the provided external services, e.g.: reconciliator services, extender services, it handles the store and retrieval of the tables uploaded by the users through the frontend application and finally, it exposes a REST API to ease the communication with the React frontend. It is built using NodeJS and Express.
Application Workflow

Before introducing each component and its functionalities, a typical workflow of the application is presented and schematized in the figure above:
- The user can start the interaction with the system by either selecting one of the uploaded tables, or by uploading a new one. Once a table is selected the user can perform actions on it. There are two kinds of actions: an action which doesn’t require a request to the backend server, e.g.: modify a table cell label, visualize some of the results, and an action which requires a request to the REST API, e.g.: save the table, query an annotation service (1).
- If the action doesn’t require a request to the server, it usually means that it is only going to update the UI data store to reflect changes to some UI component (2.2).
- Otherwise, an action may require a response from an external service (3.1), or update the current table saved to a database (3.2).
- For example, the user may require to query an external reconciliator service which provides an entity annotation for a set of cell labels (instance-level annotation), using the information and ontology from a certain KG
- For this kind of request a backend pipeline is built to ease the integration of new services. It is composed by an initial transformation of the request from the web app, so that its data is adapted to the schema necessary to query the external service. Once a response from the service is obtained, a new transformation is applied so that the annotation data is always the same when it reaches back to the UI (3.1).
- The UI always receives a standardized response, so it can easily update the data store no matter of the used external service. Once the data store is updated, the application rerenders its content to reflect the new changes (4).
- Other activities that can be performed by the user and require an interaction with the backend API are all the operations on the table files or metadata. For example, saving the current table changes requires the backend to find the table stored in the database layer to update its data (3.2).