Introduction
SemTUI is a fully modular framework for the Semantic Enrichment of Tabular Data, adoptable by both experts and non-experts in the context of semantics. Nowadays, the enrichment task is at the core of almost every data analytics pipeline, and at the same time, it proves to be also costly in both time and money. For this reason, it is important to provide data scientists with tools that guide them through the steps of the enrichment process, supporting them with interactive choices and visualizations. Semantics can bridge the gap in finding links across datasets and find solutions for the extension step, but it is important to include users in the annotation process. Indeed, the extension step is strongly related to the semantic annotation, but automatic algorithms that provide it can fail. However, if results are made available, interpretable, and editable, they can be reviewed and improved by the human’s knowledge. A study and overview of state-of-the-art tools for both the Semantic Interpretation and Enrichment task have highlighted some of their problems. They are limited by not supporting humans in the loop of the annotation process, while also not fully providing extension steps necessary to complete the enrichment of tabular data. Most of the related works also present an entry barrier for less experienced users.
Semantic Table Interpretation and Annotation
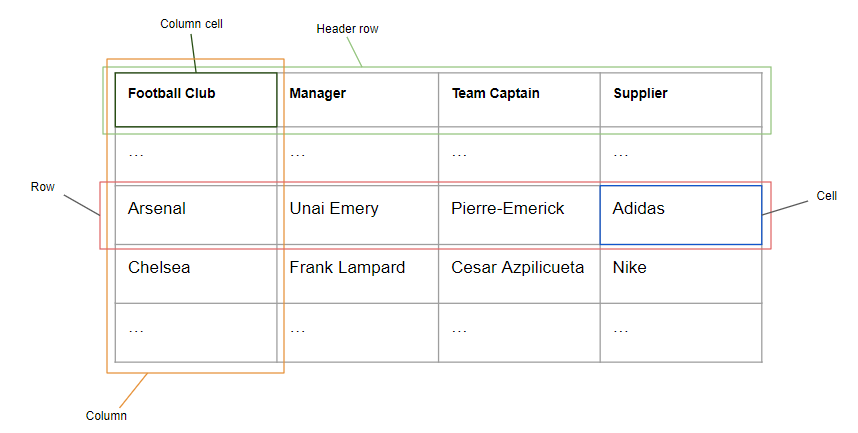
Tables are used to represent data in a structured way, but their structure does not own and give any information about the meaning of the data contained in them. In the interest of grasping any contextual meaning towards data represented in a table, tables can be aligned against ontologies. As described in the previous section, ontologies create a common and shared meaning of the knowledge contained in a particular data structure. By considering a simple table, one where the first row is the header row and the other ones contain the actual data (as shown in the figure), a set of entities denoted as M can be constructed from its rows, columns and cells. Given an ontology O defined as O = 〈V, E, L〉 where V is the set of labeled vertices representing the entities, E is the set of edges representing the relations, and L is a mapping from each edge to its label, the resulting mapping matrix between M and O represents a mapping between ontology concepts and a table entities.
A Semantic Table Interpretation (STI) approach considers each entry of the resulting matrix as a relation between a mention in the table and a concept in the ontology, of course a relation can also be missing. In other words a STI algorithm has two inputs a table and a KG and its output is a set of semantic data annotations which map mentions in the table to the KG. The result of the mapping is the original table of data enriched with semantic meanings. Different interpretations of the same table lead to different sets of semantic annotations.
The task of STI is a challenging problem due to the lack of information in a table (e.g.: missing header), noise, incompleteness, amibiguity and heterogeneity in the data. Of course, enriching a table with semantic data increases the value of the original raw data making them even more useful in different types of data analytics and data science applications. Evaluating state-of- the-art systems for STI isn’t easy and for this reason in 2019, the Semantic Web Challenge on Tabular Data to Knowledge Graph Matching (SemTab) has been established. This challenge introduced a standard terminology for the annotations resulted from an algorithm of STI and are as follow:
- Cell Entity Annotation (CEA): cell based annotation also known as istance-level annotation;
- Column Type Annotation (CTA): schema-level annotation determined to link columns to a KG ontology;
- Column Predicate Annotation (CPA): schema-level annotation determined to find binary relations (proerties of the KG ontology) between pair of columns of the table;
Those annotations may be generated separately from different interpretation tasks, while other STI approaches use the information of one annotation task to support the other. For example CEA can provide insightful information about the CTA (e.g.: the types of the annotated cells of a column might be entities of type Actor which also identify the column type). One example and state-of-the-art approach for the the automatic STI is Mantis Table presented in the SemTab 2021. This approach is also manageble from an earlier version of SemTUI called tUI. Indeed, starting from this year (2021), the SemTab challenge as well as evaluating the STI approach, also evaluates the user interface used to perform the task. This is because the challenge is becoming aware of the importance of the task even for less experienced users in the domain.
Instance-level annotation
The task of annotating the textual values in the table cells (mentions) constits of an entity linking algorithm which objective is to disambiguate mentions from the entities inside a KG. While entity linking algorithms on free text can use the contextual information given by the sorrounding words of a target entity to disambiguate between entities in the KG, on tabular data they exploit the structure of the table for both the mentions in the raw and the column of the target mention to support the result of the disambiguation.
Three primary tasks are involved into instance-level annotation in tabular data and are then combined into a single pipeline:
- Candidates retrieval: each mention of the table is matched against a target KG retrieving a candidate list of entities. The list could also be empty e.g.: the mention is a number representing a temperature in degree celsius. KGs can be huge data structures containing millions of entities therefore, indexing techniques are employed to make this step more efficient. Some state-of-the-art examples to query KGs are FactBase and Knowledge Graph Toolkit;
- Candidates Ranking: candidate entities retrieved from the previous phase are then ranked based on the combination of multiple scores, e.g.: similarity scores, and other more in depth processes;
- Decision making: based on the proofs gathered up until this phase, a decision is finally made to whether link or not the target label providing the final annotation for the considered table mention;
Different techniques can be employed to rank and decide on which of the initial candidates are going to be the annotation for a given cell. The final decision can be made by selecting the top rankings or based on thresholds, even though scores from lookup services (e.g.: Lucene score) are usually unbuonded, meaning they aren’t and can’t be normalized in an interval.
Schema-level annotation
The other task of STI, which retrieves annotation metadata for the table, is applied to its structure. The schema-level annotation task aims to map the underlying table schema to a KG ontology. Usually, this task is tackled after the instance-level annotation because of the useful insights given from the annotated cells, i.e.: types of the annotated cells give clues for the column class. The annotation of the schema involves two different types of annotation:
- Column type : a column can represent named entities (e.g.: in the previous figure Football Club, Managar, Team Captain, Supplier are all named entities), but also literal values (e.g.: dates of events). For each column, the algorithm decides whether to annotate a column as named entity, assigning one or more classes of the KG ontology, or as a literal, possibly specifying a datatype;
- Columns relations : the algorithm also tries to find the relations that might exist between each pair of columns. The task aims to annotate each pair with a property from the KG.
Semantic Table Enrichment
The raise of Big Data and the improvements of computational power in the recent years, lead to notable advancements in data analytics and data science in treating and analyzing huge amounts of data to perform various tasks of analysis and prediction. ML models starting from linear models like decision trees, SVM and up until deep learning models with transformers architecture (e.g.: BERT, GPT2-3, XLNet), require massive amounts of data, usually provided as tabular data, to be trained and achieve model generalization and are at the core of prediction analysis. Generally, studies and researches require data from multiple datasets and linking one dataset to another can be a quite difficult and troublesome task to perform, due to noise and incompleteness of data, or simply because only one type of data is initially gathered.

A typical and usual example is the following (as shown in the figure above): a business, through their applications, gathers data based on its working domain and user base. Data is then extracted from the company databases where it resides and it is then applied a filtering and data cleaning procedure (also known as data preparation step) to obtain the needed data for an analysis task. The initial set of data is usually not enough to perform the analysis and, therefore, requires enrichment using external resource datasets.
Once the original data has been enriched, data analytics can be perfomed and the results can then be presented to the end users. It is reported that about 80% of time and effort for a data analytics project resides in the step of data preparation.
It is therefore important to build and develop tools that enable data scientists an easier and capable way to perform the enrichment of a table. Semantic data can be exploited to make the enrichment process less of a struggle by introducing two core steps:
- Reconciliation: this task aims to map the mentions of the table to a target KG. The reconciliation step is mainly focused on an entity linking algorithm to perform the matching. While the reconciliation is enabled through automatic processes, they can produce ambiguous results given the ambiguity of a table mention and they are usually not enough to cover all the cases. Human knowledge and judgment is usually employed to address those issues;
- Extension: once mentions have been mapped to entities of the KG, URIs can be used to fetch new data from external data sources by making use of the Linked Data.